Learn more about Resemble's multiple generations of TTS, STS and Fill model versions such as enhanced TTS versus legacy TTS, core STS versus legacy STS, and more.
Background
Resemble’s artificial intelligence and machine learning research team is continually making state-of-the-art improvements with new techniques for voice cloning, audio synthesis and voice conversion.
To ensure access to the latest and most powerful models, Resemble’s platform provides multiple generations of model versions. The purpose of this document is to provide a high level overview of the model versions available on the platform, their associated feature scope and availability within customer plans.
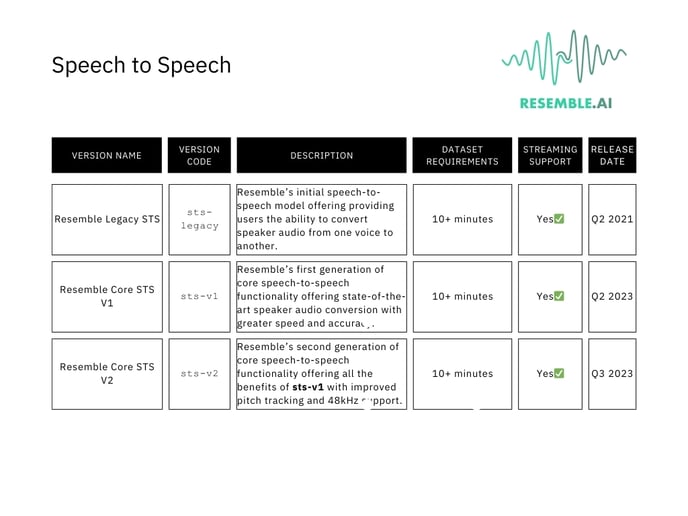
Models
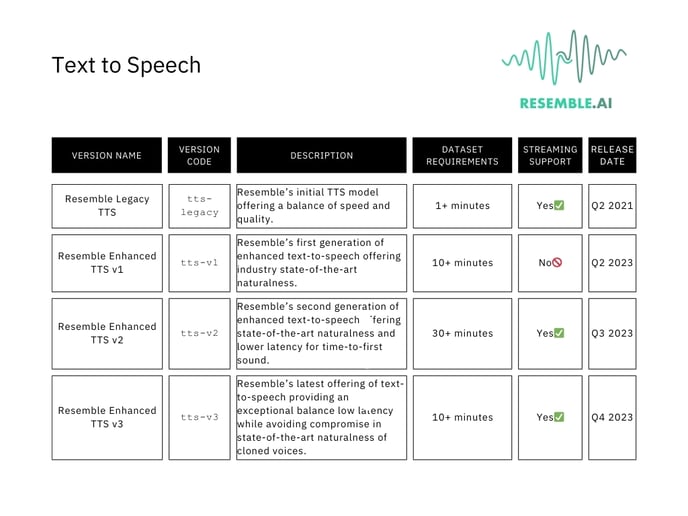
Streaming support: refers to the ability of a device or platform to play or broadcast audio, video, or other data in real-time over the internet without needing to download the entire file first. It's like watching a video on YouTube or listening to music on Spotify, where the content is delivered continuously as it's being consumed, rather than waiting for the entire file to download before playing.
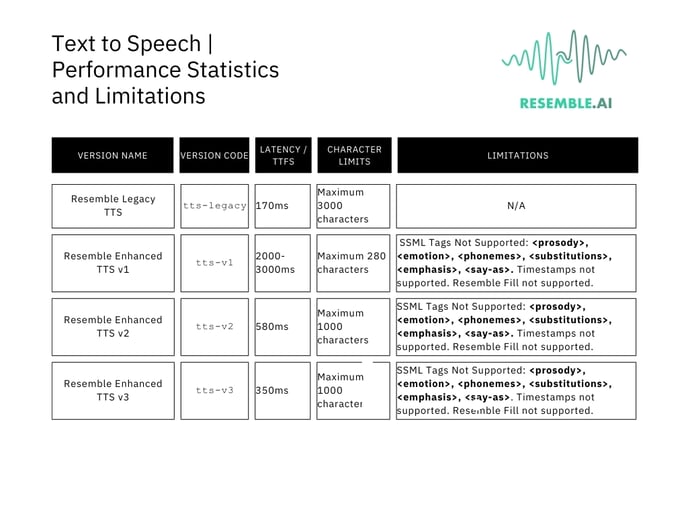
The table below provides detailed breakdown of performance statistics and limitations associated with the models.
 INFO
INFO
* Time-to-first-sound - the metrics reported are best case scenario, various factors can affect end user latency such as: load times, cold boot, network latency, and more